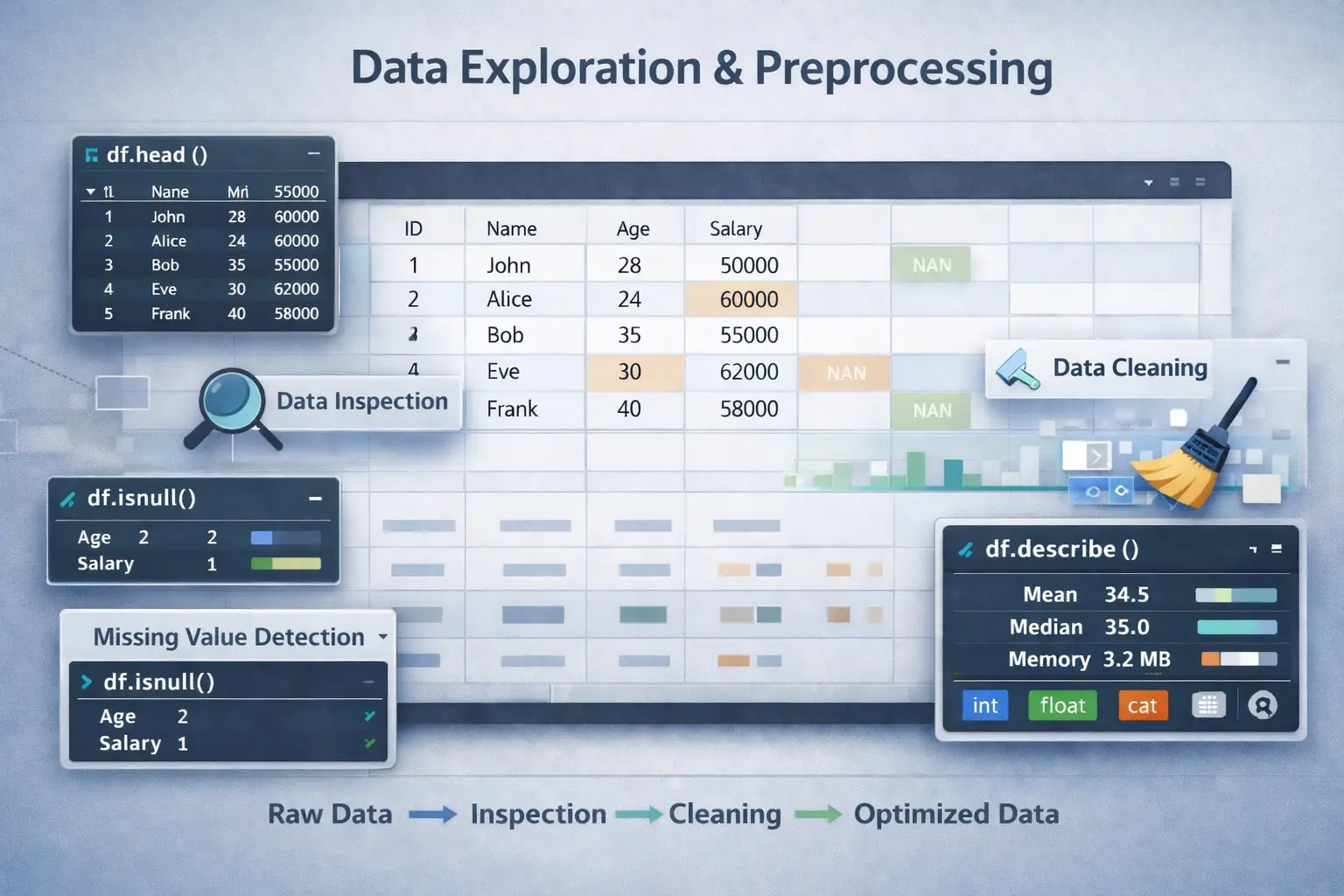
1. Data Inspection in Pandas for Effective Data Analysis
Overview
Data inspection is a fundamental step in data analysis and big data analytics workflow. It involves examining the structure, content, and quality of datasets to inform subsequent data cleaning, transformation, and modeling activities. Pandas, a widely used Python data manipulation library, offers essential functions to facilitate efficient data inspection, ensuring data quality and readiness for analysis.
Head() Function for Initial Data Preview
The head() method provides a quick glimpse of the beginning of the dataset. This initial preview helps validate the data structure, column names, and sample values. It is particularly useful for verifying that data has been loaded correctly and understanding the types of features present.
Example:
import pandas as pd
df = pd.read_csv('sales_data.csv')
print(df.head())tail() Function to View Last Records
The tail() function displays the final few rows of the dataset. This is useful in detecting issues such as incomplete data, recent updates, or data truncation at the end of files.
Example:
print(df.tail())info() Method for DataFrame Summary
The info() method provides a concise summary including data types, non-null counts, and memory usage. It gives insight into data completeness and helps identify columns with missing data.
Example:
df.info()describe() for Descriptive Statistical Analysis
The describe() function generates statistical summaries of numerical features, including mean, median, quartiles, minimum, and maximum. This enables an understanding of data distribution and the identification of outliers or anomalies.
Example:
print(df.describe())2. Handling Missing Data in Big Data Analytics for Data Quality Enhancement
Overview
Missing data can significantly compromise data analysis validity and model performance. Proper handling ensures data quality, reliability, and accuracy in big data analytics environments.
isnull() Function for Detecting Missing Values
The isnull() method identifies missing or null entries across the dataset, returning a boolean DataFrame indicating missingness. It is the first step in data quality assessment.
Example:
missing_data_mask = df.isnull()
print(missing_data_mask.sum())fillna() Method for Missing Data Imputation
The fillna() method replaces missing values with specific estimates such as mean, median, mode, or constant values. Imputation improves dataset completeness and model training stability.
Examples:
- Replacing with mean:
df['age'].fillna(df['age'].mean(), inplace=True)df['gender'].fillna('Unknown', inplace=True)Imputation maintains the integrity of the data, facilitating robust data transformation for machine learning.
dropna() for Removing Incomplete Data Records
dropna() eliminates rows or columns with missing data, enhancing data quality for precise data analysis and ensuring that models are trained on complete datasets.
Examples:
- Drop rows with any missing value:
df.dropna(inplace=True)df.dropna(axis=1, inplace=True)Drop operations are particularly useful when missing data is sparse or imputation is not appropriate.
3. Advanced Data Cleaning Techniques to Enhance Data Quality and Reliability
Overview
Beyond missing data, data cleaning involves removing duplicate records, correcting inconsistent formats, treating outliers, and rectifying erroneous entries. These steps are essential for ensuring high-quality datasets suitable for robust analytics.
Common Data Cleaning Techniques
- Removing duplicates:
df.drop_duplicates(inplace=True)Data Validation and Rules
Implement validation to enforce data correctness, such as range checks, data type constraints, and format verifications. For example, ensuring age ≥ 0 and within human lifespan limits improves data integrity.
4. Data Type Conversion & Data Casting in Pandas for Optimized Data Processing
Importance of Proper Data Types
Correct data types optimize memory usage, improve processing efficiency, and facilitate accurate analysis. For example, converting object types representing numeric data into numeric types (int, float) allows arithmetic operations.
Converting Data Types for Efficiency and Compatibility
Using astype(), data types can be transformed to better suit analysis requirements.
Example:
df['price'] = df['price'].astype(float)This conversion ensures that price, initially read as an object, is treated as numeric for calculations.
Data Casting for Proper Representation
Data casting ensures that data reflects real-world meanings correctly, such as class labels as categorical data, or date strings as datetime objects, thus supporting effective data analysis and machine learning model training.
Proper data typing streamlines data pipelines, reduces errors, and enhances computational performance when handling large datasets.
Practice Questions
- How does the head() function help in initial data inspection? Provide an example output.
- Describe how info() can guide data cleaning efforts with an example.
- Why is it critical to handle missing data before performing data analysis? Illustrate with a code example using fillna().
- What is the difference between fillna() and dropna()? When would you choose each?
- Write code to detect missing values in a dataset and then impute them with median.
- Explain how to identify outliers using descriptive statistics like the IQR method.
- Demonstrate how to remove duplicate records from a dataset using Pandas.
- Describe the importance of data type conversion in Pandas and provide a code snippet converting a column to categorical type.
- How does proper data cleaning influence the accuracy of machine learning models?
- Give an example of standardizing date formats in a dataset for consistent analysis.
Sample Code Outputs:
# Output for df.head()
ID Name Age Salary
0 1 John 28 50000
1 2 Alice 24 60000
2 3 Bob 35 55000
3 4 Eve 30 62000
4 5 Frank 40 58000
# Output for df.info()
RangeIndex: 100 entries, 0 to 99
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 100 non-null int64
1 Name 100 non-null object
2 Age 95 non-null float64
3 Salary 98 non-null float64
dtypes: float64(2), int64(1), object(1)
memory usage: 3.2 KB
# Imputing missing Age values with median
df['Age'].fillna(df['Age'].median(), inplace=True)
Recommended Study Resources
- Pandas Documentation
- W3Schools Pandas Tutorial
- GeeksforGeeks Pandas DataFrame
- DataCamp Introduction to Pandas
- Kaggle Data Cleaning Courses
This educational material aims to deepen understanding of Data Exploration & Preprocessing, emphasizing key Big Data Analytics, Data Quality, Data Transformation, and Data Imputation techniques vital for building reliable data analysis pipelines.
More Courses
- Advanced Data Analytics with Gen AI
- Data Science & AI Course
- Advanced Certificate in Python Development & Generative AI
- Advance Python Programming with Gen AI